

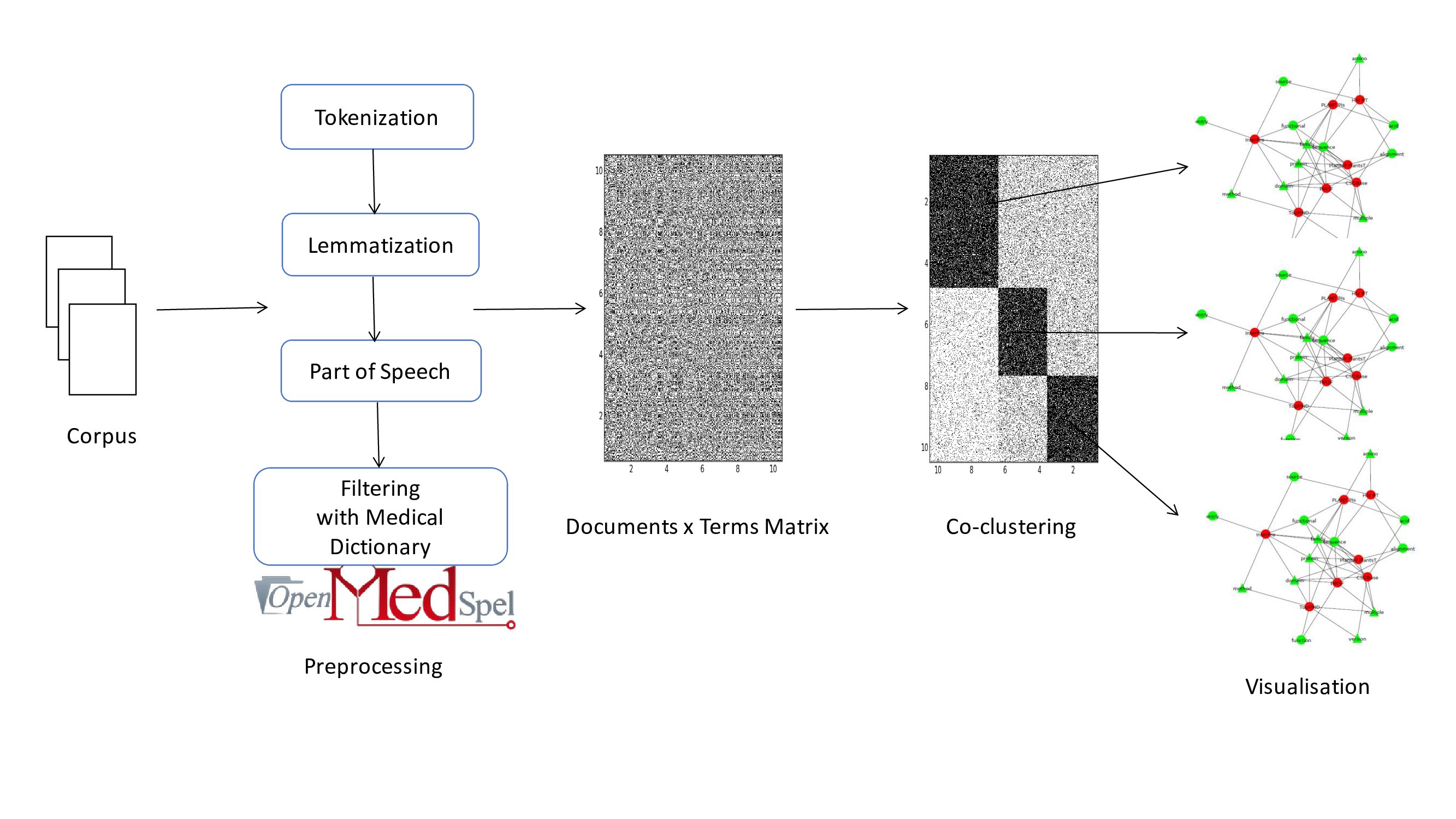
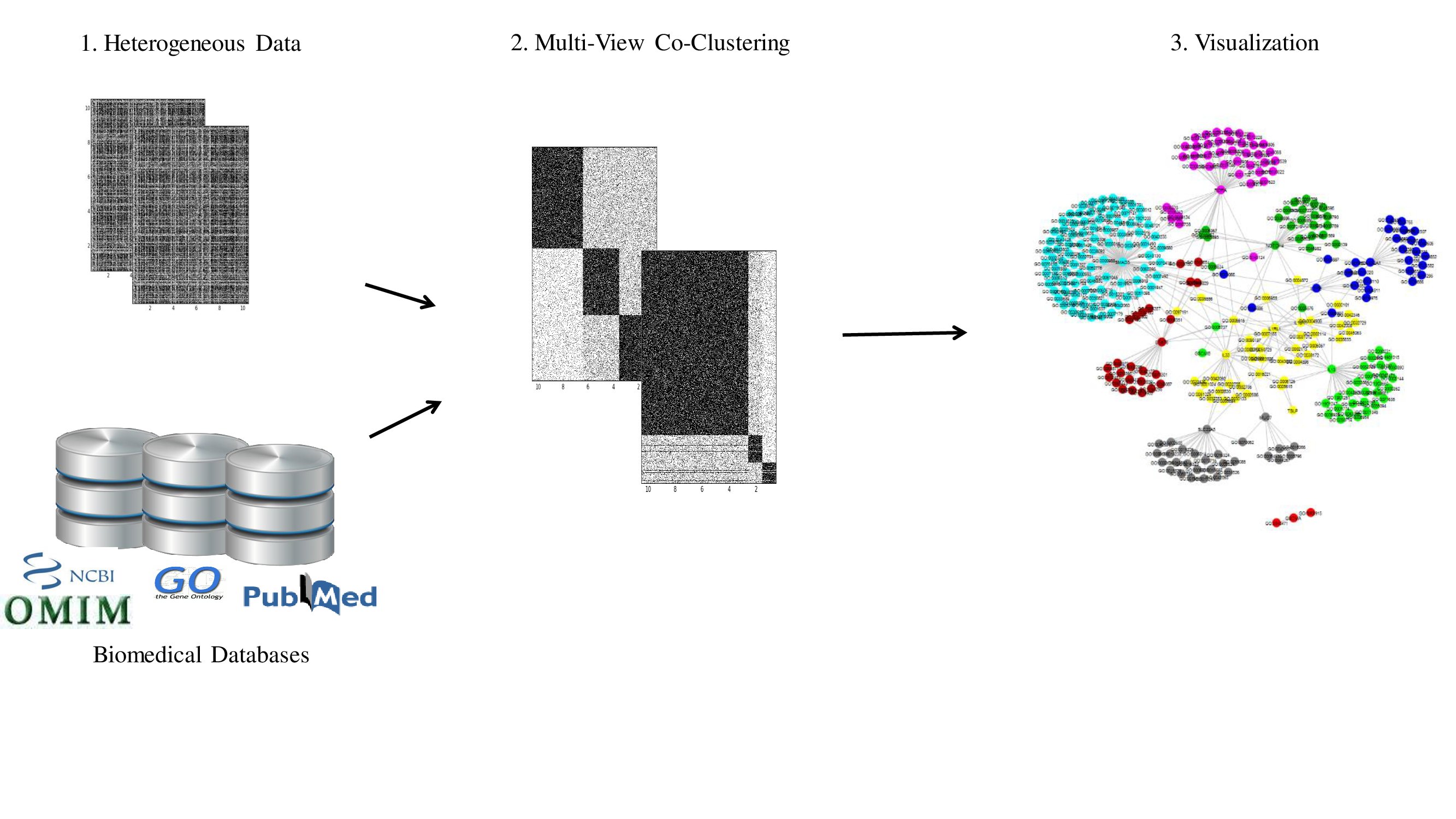
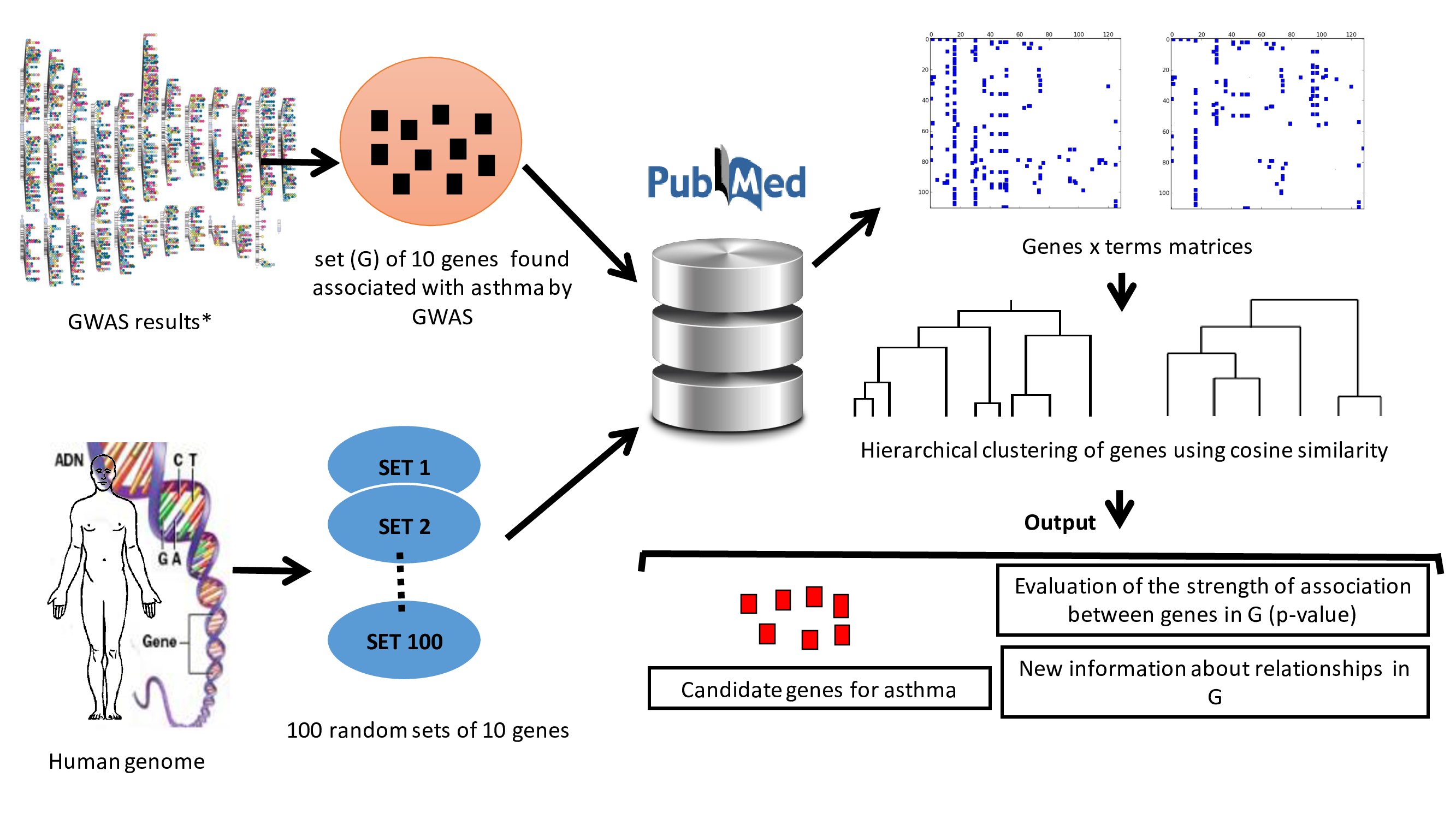
In the era of data science, it is more than ever necessary to address several challenges by Machine Learning techniques. The assessment and development of new unsupervised, semi-supervised or supervised learning methods, and sophisticated visualizations are needed.
The team MLDS at LIPADE has a long experience in this domain. It has all the necessary skills in applied mathematics and computer science to address different goals in MLDS with various approaches such as Mixture models, Factorization, graph Networks, data-visual analytics and ensemble methods. The researches of the team are realized in theoretical and applied contexts including bioinformatics, text-mining, recommender systems and computer vision. Mathematical models and algorithms are proposed to efficiently reach the objective of knowledge discovery from large and high-dimensional data.
Director
 Mohamed Nadif
Mohamed NadifAssistant Professors
 Séverine Affeldt
Séverine Affeldt François-Xavier Jollois
François-Xavier Jollois Lazhar Labiod
Lazhar Labiod Nicoleta Rogovschi
Nicoleta Rogovschi François Role
François Role Melissa Ailem
Melissa Ailem Aghiles Salah
Aghiles Salah Rafika Boutalbi
Rafika Boutalbi Florence Nocca
Florence Nocca Stanislas Morbieu
Stanislas Morbieu Nicolas Médoc
Nicolas Médoc Mohamed Cherif-Dani
Mohamed Cherif-Dani Kais Allab
Kais Allab Charlotte Laclau
Charlotte LaclauPublications
Softwares
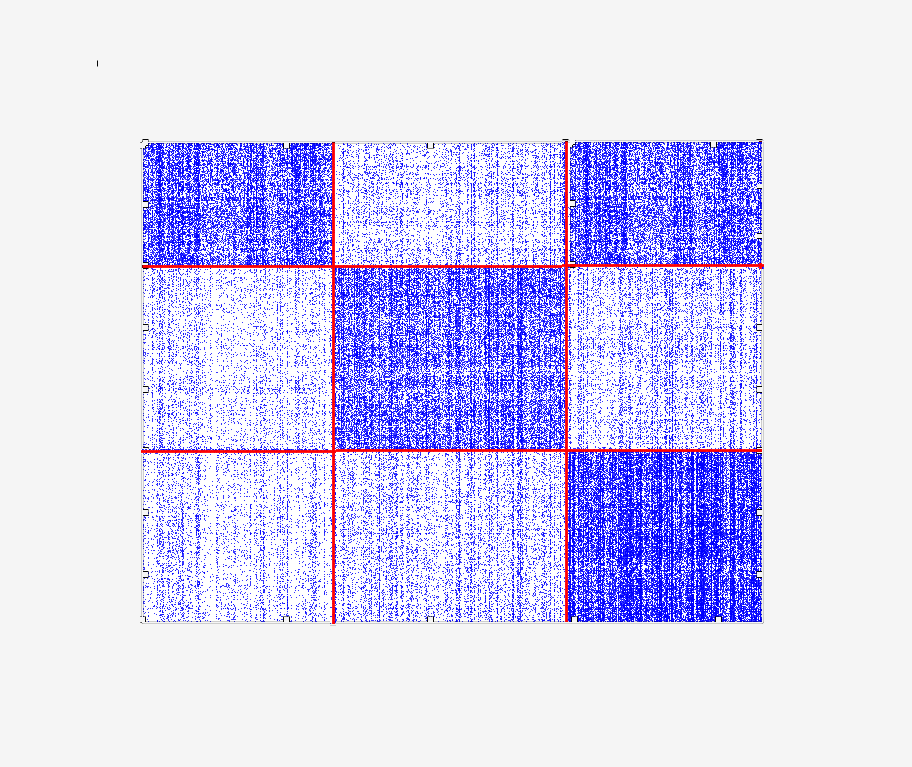
Coclust: a Python package for co-clustering
Coclust provides both a Python package which implements several diagonal and non-diagonal co-clustering algorithms, and a ready to use script to perform co-clustering.
Co-clustering (also known as biclustering), is an important extension of cluster analysis since it allows to simultaneously groups objects and features in a matrix, resulting in both row and column clusters.
Useful Links: Documentation, API, Python Package Index, Source Code, Download
Admin: François Role
Contact: francois.role@parisdescartes.fr
Contributors: Melissa Ailem, Stanislas Morbieu, Mohamed Nadif and François Role
Implemented Co-clustering Algorithms
-
CoclustMod: Ailem, Melissa, François Role, and Mohamed Nadif. Graph modularity maximization as an effective method for co-clustering text data. Knowledge-Based Systems 109 (2016): 160-173.
-
CoclustSpecMod: Labiod, Lazhar, and Mohamed Nadif. Co-clustering for binary and categorical data with maximum modularity. IEEE International Conference on Data Mining (ICDM), 2011. p. 1140-1145
-
CoclustInfo: Govaert, Gérard, and Mohamed Nadif. Mutual information, phi-squared and model-based co-clustering for contingency tables. Advances in Data Analysis and Classification (2018): 12(3):455-488
Implemented Clustering Algorithms
-
Spherical k-means: Dhillon, Inderjit S., and Dharmendra S. Modha. Concept decompositions for large sparse text data using clustering. Machine learning 42.1-2 (2001): 143-175.
Seminars
Quantification des effets directs et indirects via l'analyse de médiation
Speaker: Séverine Affeldt, University of Paris
Time: February 23, 2017, 11:00AM - 12:00AM
Location: Salle de Réunion, Espace Turing, 7 floor, 45 Rue des Saints-Pères, 75006, Paris, France
Outils de clustering diachronique pour analyser l'évolution de la production scientifique
Speaker: Nicolas DUGUE, LORIA
Time: March 10, 2016, 10:00AM - 11:00AM
Location: Salle de Réunion, Espace Turing, 7 floor, 45 Rue des Saints-Pères, 75006, Paris, France
Network reconstruction and causal inference from large scale data
Speaker: Séverine Affeldt, ICAN - Institut de Cardiométabolisme et Nutrition
Time: February 18, 2016, 10:00AM - 11:00AM
Location: Salle de Réunion, Espace Turing, 7 floor, 45 Rue des Saints-Pères, 75006, Paris, France
The Approximation of the Maximal alpha-Consensus Local Community detection problem in Complex Networks
Speaker: Patricia Conde Céspedes, L2TI - University of Paris 13
Time: February 4, 2016, 10:00AM - 11:00AM
Location: Salle de Réunion, Espace Turing, 7 floor, 45 Rue des Saints-Pères, 75006, Paris, France
Fuzzy Clustering
Speaker: Francisco Carvalho, Federal University of Pernambuco
Time: January 18, 2016, 10:30AM - 11:30AM
Location: Salle de Réunion, Espace Turing, 7 floor, 45 Rue des Saints-Pères, 75006, Paris, France
Master of Machine Learning for Data Science
In the era of data science and artificial intelligence, people with advanced skills in many areas of Machine Learning and advanced Data Analysis are in high demand. The Master II "Machine Learning for Data Science" at the University of Paris dates back to 2010 and is under the direction of Pr. Mohamed Nadif since its creation. The master aims at teaching graduate students a wide spectrum of unsupervised, semi-supervised and supervised learning as well as deep learning methods. These techniques are commonly used in the context of data science and knowledge discovery for mining and analyzing large and high dimensional data sets. The data sets can come from as various fields as genomics, text analysis, NLP, web usage mining, marketing, image and speech processing. Students are also introduced to the use of probabilistic models such as the finite mixtures models, which are important tools in machine learning.
This master II recruits students from computer science and applied mathematics masters. The selection of students is done on programming, statistics and data mining. More than a hundred applications are received every year.
Management
Director: Pr. Mohamed Nadif
Co-Director: Ass. Pr. Lazhar Labiod
Courses, Teachers in Master II and Organization
Courses: 13 UE
Supervised Learning
Deep Learning
Unsupervised Learning
Reinforcement Learning
Spatial and Temporal Data
Graphs and mediation analysis
Learning and Matrix Factorization
Finite Mixture Models and (Co)-clustering
Text-mining, NLP
Big Data Analytics
Dimensionality Reduction
English
PPD: Text-mining, NLP, recommender systems, Image, Bioinformatics, ...
Softwares and Programming languages
R
Python
SAS
Azure ML
Team MLDS and teachers
The MLDS team at LIPADE has a long experience in Machine Learning. Members of the team have the necessary skills in applied mathematics and computer science to address different goals in MLDS with various approaches such as mixture models, factorization, graph and networks analysis, data-visual analytics, ensemble methods, etc. The researches of the team are carried out in both theoretical and applied contexts, including bioinformatics, text-mining, recommender systems and computer vision. Mathematical models and algorithms are proposed to efficiently reach the objective of knowledge discovery from large and high dimensional data. The teaching team includes specialists in machine learning with PHDs in the field. They also have extensive experience with the teaching of statistical and data mining techniques.
Mohamed Nadif (Paris University)
Lazhar Labiod (Paris University)
François Role (Paris University)
Séverine Affeldt (Paris University)
Allou Samé (IFSTTAR)
Blaise Hanczar (Saclay University)
Taoufik Ennajary (Orange)
In the era of data science and artificial intelligence, people with advanced skills in many areas of Machine Learning and advanced Data Analysis are in high demand. The Master II "Machine Learning for Data Science" at the University of Paris dates back to 2010 and is under the direction of Pr. Mohamed Nadif since its creation. The master aims at teaching graduate students a wide spectrum of unsupervised, semi-supervised and supervised learning as well as deep learning methods. These techniques are commonly used in the context of data science and knowledge discovery for mining and analyzing large and high dimensional data sets. The data sets can come from as various fields as genomics, text analysis, NLP, web usage mining, marketing, image and speech processing. Students are also introduced to the use of probabilistic models such as the finite mixtures models, which are important tools in machine learning.
This master II recruits students from computer science and applied mathematics masters. The selection of students is done on programming, statistics and data mining. More than a hundred applications are received every year.
Management
Director: Pr. Mohamed Nadif
Co-Director: Ass. Pr. Lazhar Labiod
Courses, Teachers in Master II and Organization
Courses: 13 UE
Supervised Learning
Deep Learning
Unsupervised Learning
Reinforcement Learning
Spatial and Temporal Data
Graphs and mediation analysis
Learning and Matrix Factorization
Finite Mixture Models and (Co)-clustering
Text-mining, NLP
Big Data Analytics
Dimensionality Reduction
English
PPD: Text-mining, NLP, recommender systems, Image, Bioinformatics, ...
Supervised Learning
Deep Learning
Unsupervised Learning
Reinforcement Learning
Spatial and Temporal Data
Graphs and mediation analysis
Learning and Matrix Factorization
Finite Mixture Models and (Co)-clustering
Text-mining, NLP
Big Data Analytics
Dimensionality Reduction
English
PPD: Text-mining, NLP, recommender systems, Image, Bioinformatics, ...
Softwares and Programming languages
R
Python
SAS
Azure ML
R
Python
SAS
Azure ML
Team MLDS and teachers
The MLDS team at LIPADE has a long experience in Machine Learning. Members of the team have the necessary skills in applied mathematics and computer science to address different goals in MLDS with various approaches such as mixture models, factorization, graph and networks analysis, data-visual analytics, ensemble methods, etc. The researches of the team are carried out in both theoretical and applied contexts, including bioinformatics, text-mining, recommender systems and computer vision. Mathematical models and algorithms are proposed to efficiently reach the objective of knowledge discovery from large and high dimensional data. The teaching team includes specialists in machine learning with PHDs in the field. They also have extensive experience with the teaching of statistical and data mining techniques.
Mohamed Nadif (Paris University)
Lazhar Labiod (Paris University)
François Role (Paris University)
Séverine Affeldt (Paris University)
Allou Samé (IFSTTAR)
Blaise Hanczar (Saclay University)
Taoufik Ennajary (Orange)
The MLDS team at LIPADE has a long experience in Machine Learning. Members of the team have the necessary skills in applied mathematics and computer science to address different goals in MLDS with various approaches such as mixture models, factorization, graph and networks analysis, data-visual analytics, ensemble methods, etc. The researches of the team are carried out in both theoretical and applied contexts, including bioinformatics, text-mining, recommender systems and computer vision. Mathematical models and algorithms are proposed to efficiently reach the objective of knowledge discovery from large and high dimensional data. The teaching team includes specialists in machine learning with PHDs in the field. They also have extensive experience with the teaching of statistical and data mining techniques.
Mohamed Nadif (Paris University)
Lazhar Labiod (Paris University)
François Role (Paris University)
Séverine Affeldt (Paris University)
Allou Samé (IFSTTAR)
Blaise Hanczar (Saclay University)
Taoufik Ennajary (Orange)