Abstract
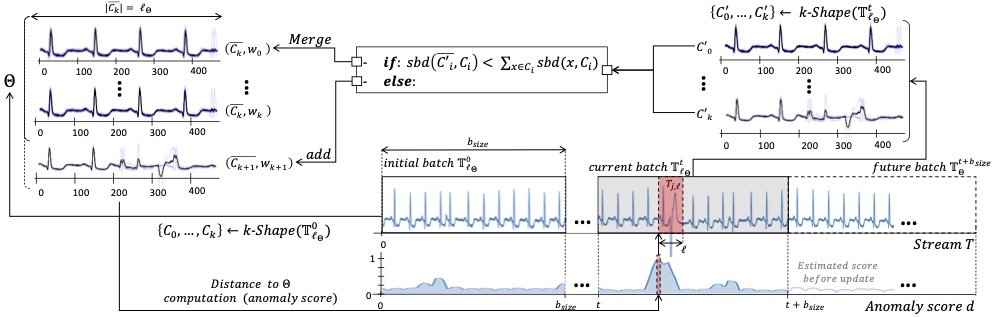
Subsequence anomaly detection in long sequences is an important problem with applications in a wide range of domains. With the increasing demand for real-time analytics and decision making, anomaly detection methods need to operate over streams of values and handle drifts in data distribution. Unfortunately, existing approaches have severe limitations: they either require prior domain knowledge or become cumbersome and expensive to use in situations with recurrent anomalies of the same type. In addition, subsequence anomaly detection methods usually require access to the entire dataset and are not able to learn and detect anomalies in streaming settings. To address these problems, we propose SAND, a novel online method suitable for domain-agnostic anomaly detection. The key idea of SAND is the detection of anomalies based on their (dis)similarity to a model that represents normal behavior. SAND relies on a novel steaming methodology to incrementally update such model, which adapts to distribution drifts and omits obsolete data. The experimental results on several real datasets demonstrate that SAND correctly identifies single and recurrent anomalies of various types, without prior knowledge of the characteristics of these anomalies. In addition, SAND outperforms by a large margin the current state-of-the-art algorithms in terms of accuracy, while achieving orders of magnitude speedups.
P. Boniol and J. Paparrizos and T. Palpanas and M. J. Franklin, SAND: Streaming Subsequence Anomaly Detection, PVLDB (2021)
P. Boniol and J. Paparrizos and T. Palpanas and M. J. Franklin, SAND in action: Subsequence Anomaly Detection for Streams, demo PVLDB (2021)