Abstract
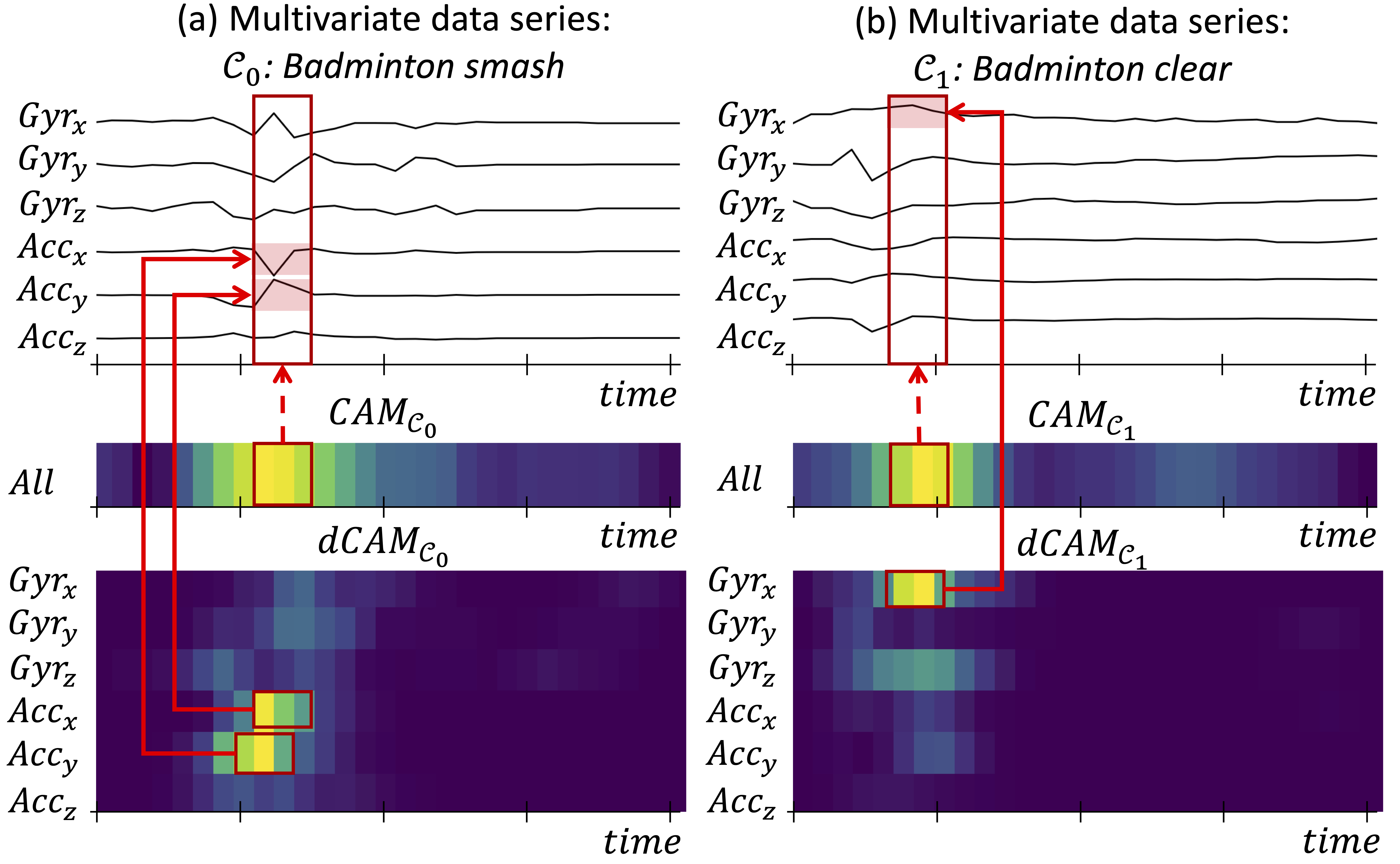
Data series classification is an important and challenging problem in data science. Explaining the classification decisions by finding the discriminant parts of the input that led the algorithm to some decision is a real need in many applications. Convolutional neural networks perform well for the data series classification task; though, the explanations provided by this type of algorithms are poor for the specific case of multivariate data series. Addressing this important limitation is a significant challenge. In this paper, we propose a novel method that solves this problem by highlighting both the temporal and dimensional discriminant information. Our contribution is two-fold: we first describe a convolutional architecture that enables the comparison of dimensions; then, we propose a method that returns dCAM, a Dimension-wise Class Activation Map specifically designed for multivariate time series (and CNN-based models). Experiments with several synthetic and real datasets demonstrate that dCAM is not only more accurate than previous approaches, but the only viable solution for discriminant feature discovery and classification explanation in multivariate time series.
Paul Boniol, Mohammed Meftah, Emmanuel Remy, and Themis Palpanas. 2022. dCAM: Dimension-wise Class Activation Map for Explaining Multivariate Data Series Classification. In Proceedings of the 2022 International Conference on Management of Data (SIGMOD ’22), June 12–17, 2022.
