Abstract
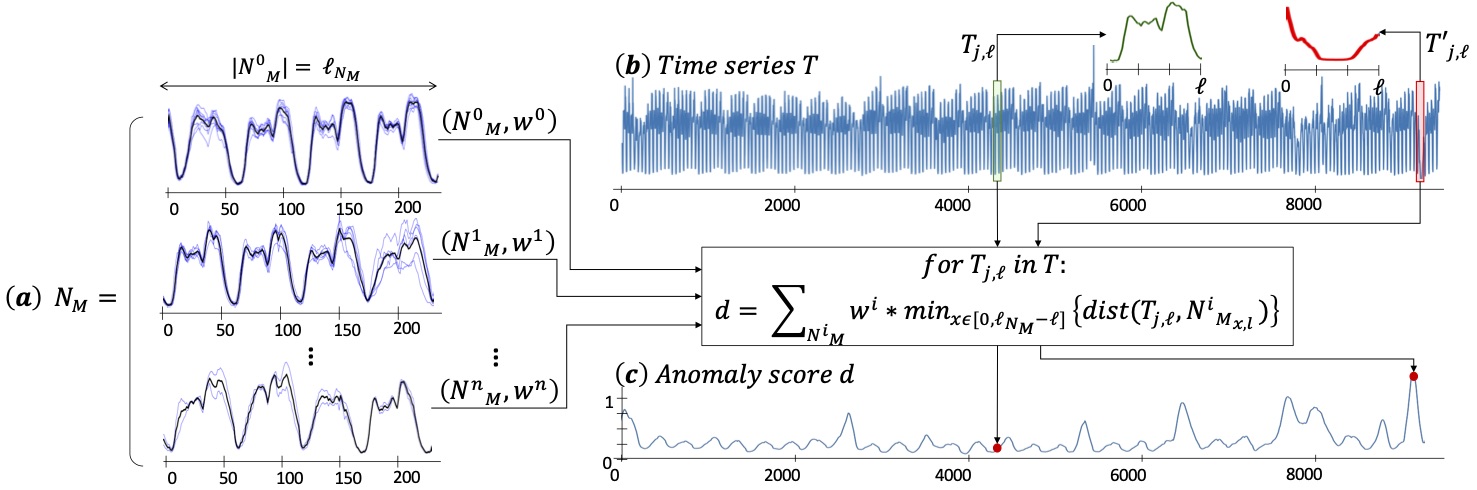
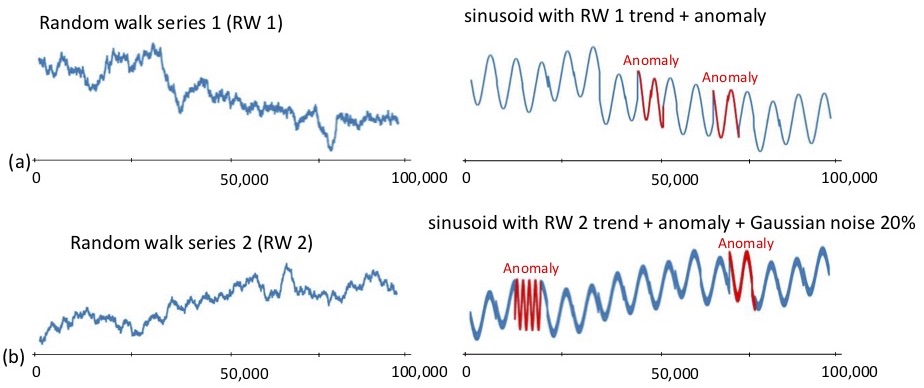
Subsequence anomaly (or outlier) detection in long sequences is an important problem with applications in a wide range of domains. However, the approaches that have been proposed so far in the literature have severe limitations: they either require prior domain knowledge, or become cumbersome and expensive to use in situations with recurrent anomalies of the same type. In this work, we address these problems, and propose NormA, a novel approach, suitable for domain-agnostic anomaly detection. % that is essentially parameter-free. NormA is based on a new data series primitive, which permits to detect anomalies based on their (dis)similarity to a model that represents normal behavior. The experimental results on several real datasets demonstrate that the proposed approach correctly identifies all single and recurrent anomalies of various types, with no prior knowledge of the characteristics of these anomalies (except for their length). Moreover, it outperforms by a large margin the current state-of-the art algorithms in terms of accuracy, while being orders of magnitude faster.
P. Boniol, M. Linardi, F. Roncallo, T. Palpanas, M. Meftah, E. Remy, Unsupervised and Scalable Subsequence Anomaly Detection in Large Data Series, VLDBJ (2021)
P. Boniol, M. Linardi, F. Roncallo, T. Palpanas, Automated Anomaly Detection in Large Sequences, IEEE ICDE (2020)
P. Boniol, M. Linardi, F. Roncallo, T. Palpanas, SAD: An Unsupervised System for Subsequence Anomaly Detection, IEEE ICDE (2020)